O que é um bot de raspagem e como construir um

Adélia Cruz
Neural Network Developer

TL;Dr: Principais pontos para construir seu bot de scraping
- Bots de scraping são programas avançados e automatizados que imitam o navegação humana para extrair dados estruturados em larga escala, diferentemente de scripts de scraping mais simples, que coletam apenas uma página.
- Bots modernos exigem ferramentas sofisticadas como Playwright ou Scrapy-Playwright para lidar com JavaScript e conteúdo dinâmico de forma eficaz.
- Medidas de segurança (limitação de taxa, CAPTCHA, fingerprinting) são o maior desafio; superá-las requer proxies, limitação de solicitações e solucionadores especializados de CAPTCHA.
- Conformidade ética e legal é inegociável; sempre respeite o
robots.txte os termos de serviço do site para evitar problemas legais. - A diferenciação em 2026 reside em integrar IA/LLMs para parser de dados mais inteligente e usar infraestrutura robusta e baseada em nuvem para operações contínuas em larga escala.
Introdução
Os dados são a vida do negócio moderno, e a capacidade de coletá-los de forma eficiente determina a vantagem competitiva. Este guia mostrará exatamente o que é um bot de scraping e como construir um que seja robusto, escalável e compatível com os padrões atuais da web. Um bot de scraping bem projetado é uma ferramenta essencial para coleta de dados na web em larga escala, transformando páginas da web em conjuntos de dados estruturados e ações. Este tutorial completo é para desenvolvedores, cientistas de dados e analistas de negócios que desejam dominar a extração automatizada de dados da internet. Cobriremos tudo, desde definições básicas e pilhas de tecnologia até as técnicas cruciais de navegação de segurança necessárias para o sucesso em 2026.
O que é um Bot de Scraping?
Um bot de scraping é um aplicativo de software autônomo projetado para navegar sites e extrair dados específicos e estruturados. Esses programas são mais complexos que scripts simples, pois são construídos para operar continuamente, lidar com estruturas de site complexas e, muitas vezes, imitar comportamento humano para evitar detecção. A função principal de um bot de scraping é automatizar a tarefa repetitiva de coletar informações, permitindo coleta de dados mais rápida e consistente do que qualquer processo manual.
Definição Básica e Como Funciona
Um bot de scraping funciona enviando solicitações HTTP para um site de destino, recebendo o conteúdo HTML e, em seguida, analisando esse conteúdo para localizar e extrair os pontos de dados desejados. A principal diferença em relação a um script básico é a capacidade do bot de manter estado, gerenciar sessões e interagir com elementos dinâmicos.
O processo geralmente segue estes passos:
- Solicitação: O bot envia uma solicitação para uma URL, geralmente usando um proxy rotativo para mascarar seu endereço IP real.
- Renderização: Para sites modernos com muito JavaScript, o bot usa um navegador headless (como Playwright ou Puppeteer) para renderizar a página, executando todo o código do lado do cliente necessário.
- Análise: O bot usa uma biblioteca de análise (como BeautifulSoup ou lxml) para navegar no Modelo de Objeto do Documento (DOM) e identificar dados alvo usando seletores CSS ou XPath.
- Extração: Os dados identificados são extraídos, limpos e transformados em um formato estruturado (ex.: JSON, CSV).
- Armazenamento: Os dados finais são armazenados em um banco de dados ou sistema de arquivos para análise posterior.
Tipos de Bots de Scraping
Não todos os bots de scraping são iguais; seu design depende fortemente da complexidade do site-alvo e da escala necessária de operação.
| Tipo de Bot | Descrição | Caso de Uso Ideal | Tecnologia Principal |
|---|---|---|---|
| Script Simples | Executa uma única solicitação e analisa HTML estático. Não é um "bot" verdadeiro. | Pequenos sites estáticos sem JavaScript. | requests, BeautifulSoup |
| Bot de Automação de Navegador | Usa um navegador headless para renderizar JavaScript e simular interação humana. | Sites dinâmicos, aplicações de página única (SPAs), login necessário. | Selenium, Puppeteer, Playwright |
| Bot Distribuído | Uma rede de bots executando em múltiplas máquinas ou funções em nuvem, gerenciada por um orquestrador central. | Projetos de scraping em larga escala com alta volume de dados. | Scrapy, Kubernetes, Cloud Functions |
| Bot com Inteligência Artificial | Integra Modelos de Linguagem de Grande Escala (LLMs) para analisar dados não estruturados ou resolver desafios de segurança complexos. | Extração de dados de conteúdo de texto altamente variável ou não estruturado. | APIs de LLM, Protocolo de Contexto de Modelo (MCP) |
Estatísticas Importantes sobre Bots de Scraping
O uso de bots de scraping é uma indústria enorme e em crescimento, impulsionada pela demanda por inteligência de mercado em tempo real. De acordo com relatórios recentes da indústria, o mercado global de scraping de web deve atingir mais de 10 bilhões de dólares até 2027, crescendo a uma taxa anual composta (CAGR) superior a 15% Grand View Research: Tamanho, Participação e Análise do Relatório do Mercado de Scraping de Web. Além disso, uma parte significativa de todo o tráfego da internet – estimada em mais de 40% – é não humana, com uma grande porcentagem atribuída a bots legítimos e sofisticados, incluindo crawlers de mecanismos de busca e bots de scraping comerciais. Esses dados reforçam a necessidade de construir bots altamente eficazes e resistentes para competir no cenário atual de dados.
Por que Construir e Usar um Bot de Scraping?
A decisão de construir um bot de scraping geralmente é motivada pela necessidade de dados que não estão disponíveis por meio de APIs ou exigem monitoramento em tempo real.
1. Inteligência Competitiva e Pesquisa de Mercado
Empresas usam bots de scraping para ganhar vantagem competitiva. Por exemplo, uma empresa de comércio eletrônico pode monitorar preços de concorrentes, níveis de estoque e descrições de produtos em tempo real. Isso permite ajustes dinâmicos de preços, garantindo que permaneçam competitivos. Esta é uma aplicação essencial do scraping de web para pesquisa de mercado.
2. Agregação de Conteúdo e Geração de Leads
Empresas de mídia e plataformas especializadas usam bots para aglutinar conteúdo de várias fontes, criando um recurso centralizado valioso para seus usuários. Da mesma forma, equipes de vendas usam bots para extrair informações de contato e detalhes de empresas de diretórios públicos, alimentando seus canais de geração de leads.
3. Automação e Eficiência
Um bot de scraping pode executar tarefas em minutos que levariam a um humano centenas de horas. Essa eficiência é crítica para tarefas como coleta de dados financeiros, pesquisa acadêmica e monitoramento de conformidade em milhares de páginas da web. A capacidade de automatizar esse processo é a razão principal pela qual as empresas investem em aprender como construir um bot de scraping. O caso marcante de hiQ Labs, Inc. v. LinkedIn Corp. esclareceu ainda mais a legalidade de scraping de dados disponíveis publicamente.
Como Construir Seu Bot de Scraping: Guia Passo a Passo
Aprender a construir um bot de scraping envolve uma abordagem estruturada, passando da planejamento inicial até a implantação e manutenção.
Passo 1: Definir Escopo e Ética
Antes de escrever qualquer código, defina claramente os pontos de dados que você precisa e os sites-alvo. Crucialmente, você deve verificar o arquivo robots.txt do site, que especifica quais partes do site os crawlers são permitidos a acessar. Sempre siga os termos de serviço do site. Ignorar essas diretrizes pode levar a banimento de IP, ações legais ou violações éticas. Para uma compreensão detalhada de conformidade, consulte O guia oficial do Google sobre robots.txt.
Passo 2: Escolher a Pilha de Tecnologia Certa
A pilha de tecnologia é determinada pela complexidade do site-alvo. Para sites modernos, um framework de automação de navegador é essencial.
| Componente | Sites Estáticos (Simples) | Sites Dinâmicos (Complexos) |
|---|---|---|
| Linguagem | Python, Node.js | Python, Node.js |
| Cliente HTTP | requests (Python) |
Gerenciado pelo framework de automação de navegador |
| Parser | BeautifulSoup, lxml |
Playwright, Puppeteer (usando seu acesso interno ao DOM) |
| Framework | Nenhum/Script Personalizado | Scrapy, Scrapy-Playwright |
| Segurança | Rotação básica de User-Agent | Proxies, Solucionadores de CAPTCHA, Gerenciamento de Fingerprint |
Para um tutorial robusto sobre bots de scraping em 2026, recomendamos Python devido ao seu rico ecossistema de Melhores Bibliotecas de Scraping de Web em Python 2026. Em particular, o Scrapy é um framework poderoso para projetos em larga escala.
Passo 3: Implementar Técnicas de Navegação de Segurança
Este é o parte mais desafiadora do scraping de web. Os sites empregam ativamente medidas de segurança para prevenir a extração de dados automatizada não autorizada.
A. Limitação de Solicitações e Rotação de IP
Para evitar limitação de taxa, seu bot deve introduzir atrasos aleatórios entre solicitações. Mais importante, você deve usar uma rede de proxy confiável para rotacionar seu endereço IP. Isso faz com que pareça que as solicitações vêm de muitos usuários diferentes. Aprenda estratégias eficazes para Como Evitar Banimento de IP ao Usar Solucionador de CAPTCHA em 2026.
B. Lidando com Conteúdo Dinâmico e Fingerprinting
Use um navegador headless como Playwright para garantir que o JavaScript seja executado, renderizando a página exatamente como um usuário humano a veria. Documentação Oficial do Playwright mostra que é frequentemente preferido em relação a ferramentas mais antigas como Selenium, pois oferece melhor controle sobre o fingerprinting do navegador, que é um método-chave que os sistemas de segurança usam para identificar bots.
C. Resolução de CAPTCHA
Quando um desafio de CAPTCHA aparece, seu bot não pode prosseguir. Você deve integrar um serviço especializado para resolvê-lo. Esses serviços usam IA para resolver desafios de imagem e texto automaticamente. Escolher o solucionador de CAPTCHA certo é crucial para manter o tempo de atividade do bot. Você pode comparar Os Melhores 5 Solucionadores de CAPTCHA para Scraping de Web em 2026 para encontrar a opção mais confiável. Por exemplo, você pode integrar um Melhor Solucionador de reCAPTCHA 2026 para Automação e Scraping de Web para lidar com desafios comuns.
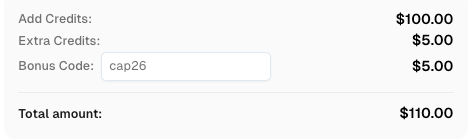
Use o código
CAP26ao se cadastrar no CapSolver para receber créditos extras!
Passo 4: Limpeza de Dados, Armazenamento e Agendamento
Após a extração dos dados, eles devem ser limpos (ex.: remoção de tags HTML, padronização de formatos) e armazenados. Para operação contínua, o bot deve ser agendado para executar periodicamente usando ferramentas como Cron jobs ou agendadores nativos da nuvem. Isso garante que seus dados permaneçam atualizados e relevantes para o scraping de web para pesquisa de mercado.
Passo 5: Monitoramento e Manutenção
Sites alteram sua estrutura frequentemente. Seu bot de scraping inevitavelmente quebrará. Implemente loggin robusto e monitoramento para alertá-lo quando o bot falhar. Manutenção regular e adaptação de seus seletores a novos layouts de site são tarefas contínuas para qualquer operador de bot de scraping bem-sucedido.
Estudo de Caso: Bot de Monitoramento de Preços em E-commerce
Uma empresa de eletrônicos de médio porte precisava monitorar os preços de seus 500 produtos principais em três sites de concorrentes importantes a cada hora.
- Desafio: Os sites dos concorrentes usavam medidas de segurança agressivas, incluindo o Turnstile da Cloudflare e fingerprinting avançado do navegador.
- Solução: Eles construíram um bot de scraping distribuído usando Scrapy-Playwright, implantado em uma plataforma em nuvem. Eles integraram um serviço premium de proxies para rotação de IP e usaram um serviço especializado para resolver desafios da Cloudflare.
- Resultado: O bot alcançou uma taxa de sucesso de 99%, fornecendo dados de preços em tempo real que permitiram à empresa implementar uma estratégia de preços dinâmicos. Dentro de seis meses, essa estratégia levou a um aumento de 12% no volume de vendas dos produtos monitorados. Isso demonstra o poder de um bot de scraping bem projetado.
Conclusão e Chamada para Ação
Compreender o que é um bot de scraping e como construí-lo já não é opcional; é uma habilidade fundamental na economia baseada em dados. Um bot de scraping sofisticado é uma ferramenta poderosa para extração automatizada de dados, oferecendo eficiência e profundidade sem precedentes em inteligência de mercado. O sucesso depende de técnicas robustas de navegação de segurança, uma pilha de tecnologia moderna e compromisso com práticas éticas de scraping.
Para garantir que seu bot permaneça operacional contra as defesas de segurança mais avançadas, você precisa de ferramentas confiáveis. Explore como um solucionador profissional de CAPTCHA pode se integrar de forma fluida ao fluxo de trabalho do seu bot, garantindo fluxo contínuo de dados mesmo diante de desafios complexos.
Perguntas Frequentes: Perguntas Mais Comuns
Q1: É legal construir um bot de scraping?
A legalidade do scraping de web é complexa e altamente dependente da jurisdição, dos termos de serviço do site e da natureza dos dados. Geralmente, o scraping de dados disponíveis publicamente é frequentemente permitido, mas o scraping de dados atrás de um login ou violação do arquivo robots.txt do site é arriscado. Sempre busque orientação jurídica e priorize práticas éticas.
Q2: Qual a diferença entre um bot de scraping e um web crawler?
Um web crawler (como o Googlebot) é projetado para indexar a web inteira ou uma grande parte dela, focando em descobrir links e mapear a estrutura da internet. Um bot de scraping é altamente direcionado, focando em extrair pontos de dados específicos de um conjunto limitado de páginas ou sites. Um bot de scraping frequentemente incorpora funcionalidade de crawling, mas seu objetivo principal é extração de dados, não indexação.
Q3: Como posso evitar que meu bot de scraping seja bloqueado?
A estratégia mais eficaz é imitar o comportamento humano: use um navegador headless, rotacione endereços IP com proxies de alta qualidade, introduza atrasos aleatórios entre solicitações e gerencie o fingerprint do seu navegador. Quando desafios como CAPTCHA ou Cloudflare aparecerem, integre um serviço especializado de resolução de desafios de segurança para resolvê-los automaticamente.
Q4: Qual o papel da IA em bots de scraping modernos?
A IA está transformando o scraping de web de duas formas principais: primeiro, na resolução de desafios de segurança (solucionadores de CAPTCHA com IA); e segundo, na análise de dados. LLMs podem ser usados para extrair dados estruturados de textos altamente não estruturados (ex.: avaliações de produtos ou artigos de notícias), uma tarefa com a qual bots tradicionais baseados em seletores têm dificuldade.
Q5: Posso usar um proxy gratuito para meu bot de scraping?
Proxies gratuitos são altamente imprevisíveis, lentos e frequentemente já estão na lista negra de grandes sites. Eles aumentarão significativamente sua taxa de bloqueio e comprometerão a integridade dos seus dados. Para qualquer projeto sério de raspagem de web, você deve investir em um serviço premium de proxy residencial ou de ISP.
Ver mais
web scrapingApr 22, 2026
Arquitetura de Web Scraping em Rust para Extração de Dados Escalável
Aprenda arquitetura de raspagem web escalável em Rust com reqwest, scraper, raspagem assíncrona, raspagem de navegador headless, rotação de proxies e tratamento de CAPTCHA compatível.
web scrapingApr 08, 2026
Selenium vs Puppeteer para Resolução de CAPTCHA: Comparação de Desempenho e Caso de Uso
Compare o Selenium vs Puppeteer para resolver CAPTCHA. Descubra benchmarks de desempenho, notas de estabilidade e como integrar o CapSolver para o máximo de sucesso.

